- 이미지 분류: 이미지가 어떤 객체인가?
- Object Detection: 어디에 어떤 객체가 있는가?
Object Detection 특징
- 전처리 (Pre-processing)
- 특징 추출 (Feature Extraction)
- 분류 (Classifier)
R-CNN 계열(2-stage) vs YOLO(1-stage) 비교
1) R-CNN 계열 주요 아이디어
- 이미지를 영역 제안(Region Proposal) 을 통해 여러 개의 작은 후보로 나눈다.
- 후보 각각을 CNN에 입력해 특징을 추출한다.
- 추출된 특징 벡터를 분류기(SVM)에 입력해 객체를 분류한다.
- Bounding Box Regression을 통해 위치를 보정한다.
2) YOLO 주요 아이디어
- 이미지 입력 및 CNN 처리하여 특징 추출 및 정보 생성한다.
- Bounding Box 및 클래스 예측을 통해 객체 위치 및 클래스 예측한다.
- Non-Maximum Suppression(NMS)을 통해 중복된 박스 제거 및 최종 객체 결정한다.
- 이미지를 단 한번만 호출 하고, 동시에 각 영역에 가중치를 부여함 ( 분류 + location 동시에 가능)
- 실시간 (real time) 영상에 특화됨
R-CNN vs YOLO 차이
YOLO에서 오버헤드(Overrhead)가 크게 감소
*Overhead: 어떤 작업을 수행하기 위해 추가적으로 필요한 시간, 자원, 계산량 등,
- R-CNN 계열은 Region Proposal 후보를 수천개 제안
- YOLO는 총 7x7x2 = 98개의 연산 후보를 제안
| 항목 | R-CNN 계열 | YOLO |
| 구조 | Region Proposal 단계 + CNN 탐지 단계(2-stage) | 단일 CNN 구조(1-stage) |
| Region Proposal | Selective Search 사용 → 매우 느림 | Region Proposal 단계 없음 |
| 복잡도 | Region Proposal 단계와 CNN 단계에서 연산 반복 → 연산량 증가 | CNN Forward Pass 한 번에 해결 |
| 속도 | 매우 느림 → 실시간 탐지 불가 | 매우 빠름 → 실시간 탐지 가능 (FPS > 30) |
| 성능 | 높은 정확도 | 정확도는 조금 떨어짐 (하지만 속도는 빠름) |
| 활용 분야 | 정밀한 객체 탐지 ( 의료) | 실시간 탐지 (영상) |
YOLO 등장 개념
바운딩 박스 (bounding box) : 최종 객체 검출 영역
- 객체가 존재하는 위치를 나타내는 직사각형 상자입니다.
- YOLO는 (x, y, w, h) 값으로 경계 상자를 예측합니다.
- (x, y): 경계 상자의 중심 좌표
- (w, h): 경계 상자의 너비와 높이

ROI (region of interest) : 관심있는 지역
- 분석하고자 하는 특정 영역을 의미합니다.
- 이미지에서 전체가 아닌 특정 부분만 선택해 처리할 때 사용됩니다.

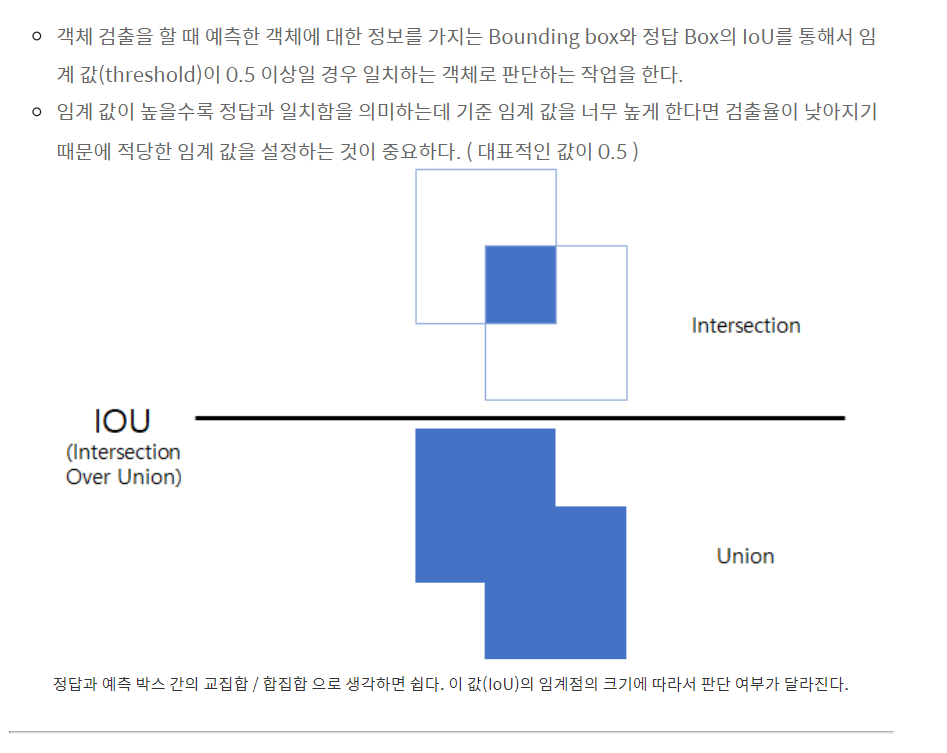
IOU: Intersection over Union
- 예측한 Bounding Box와 실제 객체의 Bounding Box 간 겹치는 정도를 나타내는 지표입니다.

NMS: Non Maximum Suppression
- YOLO는 같은 객체에 대해 여러 개의 Bounding Box를 출력할 수 있습니다.
- NMS는 겹치는 박스 중 신뢰도가 가장 높은 것만 선택하고 나머지는 제거합니다

YOLO 구조 살펴보기

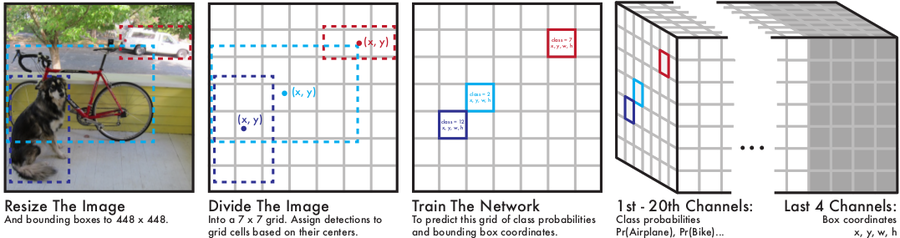
- 입력 이미지 448 x 448 x 3 (RGB) 크기에 맞춰 변환한 뒤, CNN에 입력합니다.
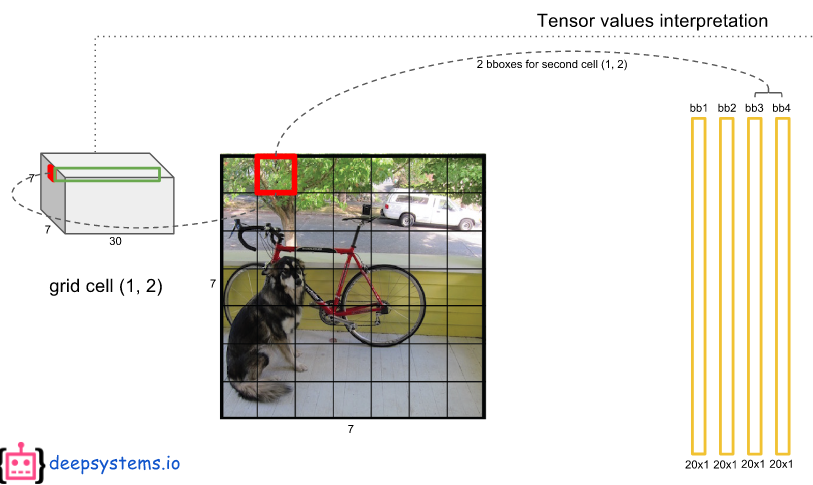
- 이미지를 7x7 크기의 그리드 셀로 나눔 (총 49개 셀)
- 각 그리드셀에서 다음 정보를 출력→ 총 30개 :
- Bounding Box 2개 → 각 Box당 5개 값 (x, y, w, h, c)
- 클래스 확률 (20개) → VOC 데이터셋 기준 클래스 수
빨간색 그리드셀 위치에서 예측한 노란색 바운딩 박스 2개
: 각 그리드 셀은 최대 두 개의 Bounding Box를 예측
| 값 | 설명 |
| x,y | 그리드 셀 내에서 Bounding Box의 중심 좌표 |
| w,h | 전체 이미지 기준 Bounding Box의 너비 및 높이 |
| c | Bounding Box의 신뢰도 (Confidence), 객체가 있을 확률 |


그리드셀에서 존재하는 20개 클래스 예측 확률
- 각 그리드 셀은 20개의 클래스 확률을 출력
- 클래스 예측 예시:
- 개 (Dog) → 0.8
- 자전거 (Cat) → 0.1
- 자동차 (Car) → 0.05


NMS 단계
- 여러 개의 중복된 박스 중에서 가장 신뢰도가 높은 박스를 남기고 나머지는 제거
- 예를들어, IoU(Intersection over Union)가 일정 값(예: 0.5) 이상이면 중복된 것으로 판단하고 제거

YOLO 작동 알고리즘 정리
OpenCV 실습
- 실시간 이미지 및 비디오 처리용 오픈소스 라이브러리 (C++, Python 지원)
- YOLO가 객체를 탐지 시 이미지를 불러오고, 전처리하고, 결과를 시각화하는 작업에서 openCV 필요
OpenCV 활용 범위
- 이미지 및 영상 데이터 처리
- YOLO에 입력할 이미지나 영상을 OpenCV로 읽기
- YOLO가 탐지한 결과 이미지를 OpenCV로 표시
- 전처리 필수 도구
- YOLO가 정확히 탐지할 수 있도록 이미지 크기 조정
- 노이즈 제거, 색상 변환 등 전처리 작업 수행
- 결과 시각화
- YOLO가 탐지한 객체를 Bounding Box로 표시
- 탐지 결과에 텍스트 추가 및 저장
- 속도가 빠르고 효율적
- C++ 기반 → 연산 속도 빠름
- Python 지원 → 코드 작성이 간단함
- 다양한 딥러닝 모델과 연동 가능
- YOLO, Faster R-CNN 등 객체 탐지 모델에서 사용 가능